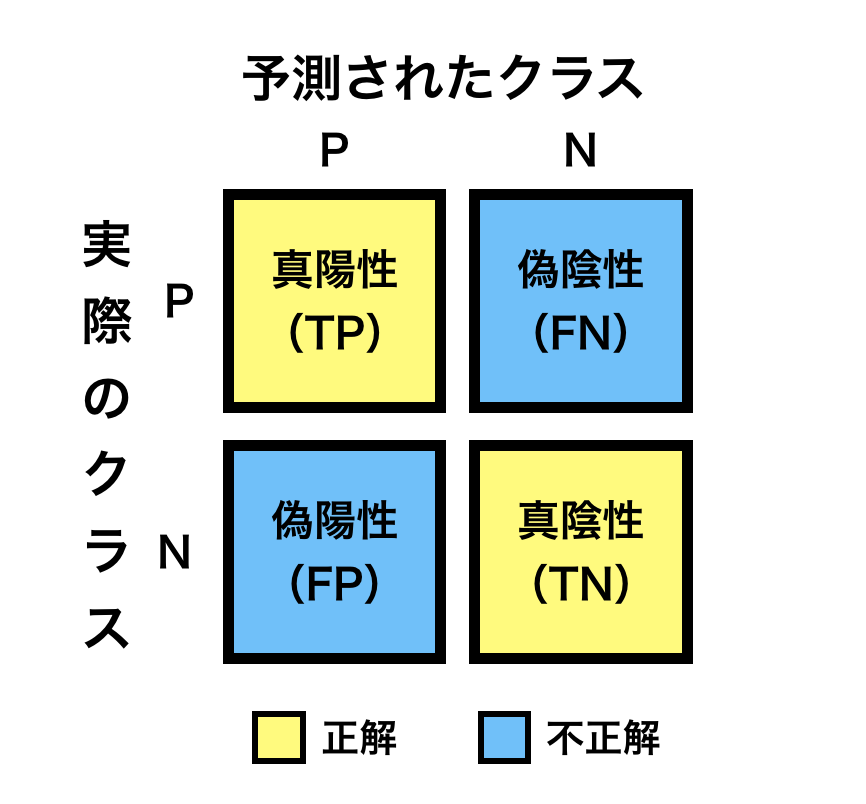
真陽性は陽性クラスと予測され結果も陽性クラスであった個数 真陰性は陰性クラスと予測され結果も陰性クラスであった個数 偽陽性は陽性クラスと予測されたが結果は陰性クラスであった個数 偽陰性は陰性クラスと予測されたが結果は陽性クラスであった個数 真陽性(True Positive)と真陰性(True Negative)は機械学習モデルが正解し、 偽陽性(False Positive)と偽陰性(False Negative)は機械学習モデルが不正解 正解率(accuracy):本来ポジティブに分類すべきアイテムをポジティブに分類し、本来ネガティブに分類すべきアイテムをネガティブに分類できた割合 TP + TN / FP + FN + TP + TN 適合率 (precision):ポジティブに分類されたアイテムのうち、実際にポジティブであったアイテムの割合 TP / FP + TP 検出率 (recall):本来ポジティブに分類すべきアイテムを、正しくポジティブに分類できたアイテムの割合 TP / FN + TP F値 :適合率(Precision) と検出率 (Recall) をバランス良く持ち合わせているかを示す指標。
from sklearn.metrics import confusion_matrix y_true = [0, 0, 0, 0, 1, 1, 1, 0, 1, 0] y_pred = [0, 0, 0, 0, 1, 1, 1, 1, 0, 1] tp, fn, fp, tn = confusion_matrix(y_true, y_pred).ravel() (tp, fn, fp, tn) (4, 2, 1, 3) #正解率 from sklearn.metrics import accuracy_score y_true = [0, 0, 0, 0, 1, 1, 1, 0, 1, 0] y_pred = [0, 0, 0, 0, 1, 1, 1, 1, 0, 1] accuracy_score(y_true, y_pred) 0.69999999999999996 #適合率 from sklearn.metrics import precision_score y_true = [0, 0, 0, 0, 1, 1, 1, 0, 1, 0] y_pred = [0, 0, 0, 0, 1, 1, 1, 1, 0, 1] precision_score(y_true, y_pred) 0.59999999999999998 #検出率 from sklearn.metrics import recall_score y_true = [0, 0, 0, 0, 1, 1, 1, 0, 1, 0] y_pred = [0, 0, 0, 0, 1, 1, 1, 1, 0, 1] recall_score(y_true, y_pred) 0.75 #F値 from sklearn.metrics import f1_score y_true = [0, 0, 0, 0, 1, 1, 1, 0, 1, 0] y_pred = [0, 0, 0, 0, 1, 1, 1, 1, 0, 1] f1_score(y_true, y_pred) 0.66666666666666652
 rise
rise